
La crescente mole di dati disponibili grazie alle nuove tecnologie sta portando a ripensare il modo in cui viene misurata l’attività economica
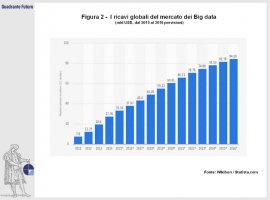
La rapida diffusione globale dell’accesso a internet e la diffusione di nuove tecnologie permettono oggi l’accumulo di una crescente mole di dati: ogni due giorni se ne producono tanti quanti quelli generati dall’intera umanità prima del 2003, e il ritmo di accumulo cresce ad un tasso annuo del 40% (Figura 1).
Si tratta dei cosiddetti big data, insiemi estremamente grandi di informazioni che possono essere analizzati attraverso computer per rivelare modelli e tendenze.
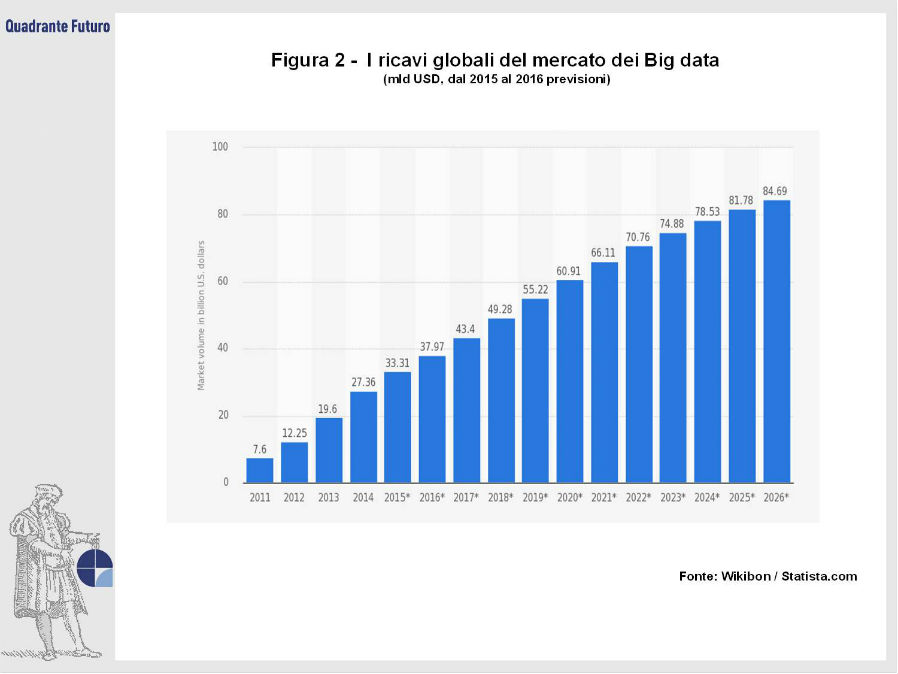
Dopo aver contribuito ad innovare diversi campi, tra cui il marketing, i trasporti e le assicurazioni, questa montagna di informazioni, unita agli avanzamenti tecnologici nel campo dell’elaborazione dei dati, sta oggi portando a ripensare il modo in cui viene misurata l’attività economica. La possibilità di disporre di dati economici in maniera repentina ed affidabile riveste infatti un’importanza chiave per gli attori dei mercati finanziari e i policy-maker di ogni parte del mondo (Figura 2). Tuttavia è possibile evidenziare una forte disuguaglianza nella disponibilità e qualità dei dati tra i paesi ricchi, dove sono presenti robusti sistemi ufficiali per la registrazione dei dati demografici ed economici, e quelli più arretrati, che spesso raccolgono le informazioni sulla popolazione rurale solamente tramite questionari condotti porta a porta su piccoli campioni, una metodologia poco precisa e molto costosa da scalare. Solo 12 dei 49 paesi sub-sahariani hanno condotto un censo sull’intera popolazione degli ultimi 10 anni.
L’assenza di dati affidabili riguardo al reddito e al consumo delle regioni più arretrate dei paesi in via di sviluppo rappresenta un significativo ostacolo alla lotta alla povertà. Se le organizzazioni internazionali stimano oggi che circa un miliardo di persone vivano sotto la soglia di povertà, nella pratica distinguere all’interno di un paese arretrato quali siano le zone in cui si trovano le fasce più bisognose della popolazione risulta spesso estremamente difficile, e questo impedisce ai policy-maker e alle organizzazioni umanitarie di disegnare le misure più adatte per combatterla, di misurare i progressi compiuti e di destinare le risorse disponibili verso le zone che più le necessitano.

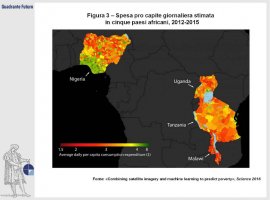

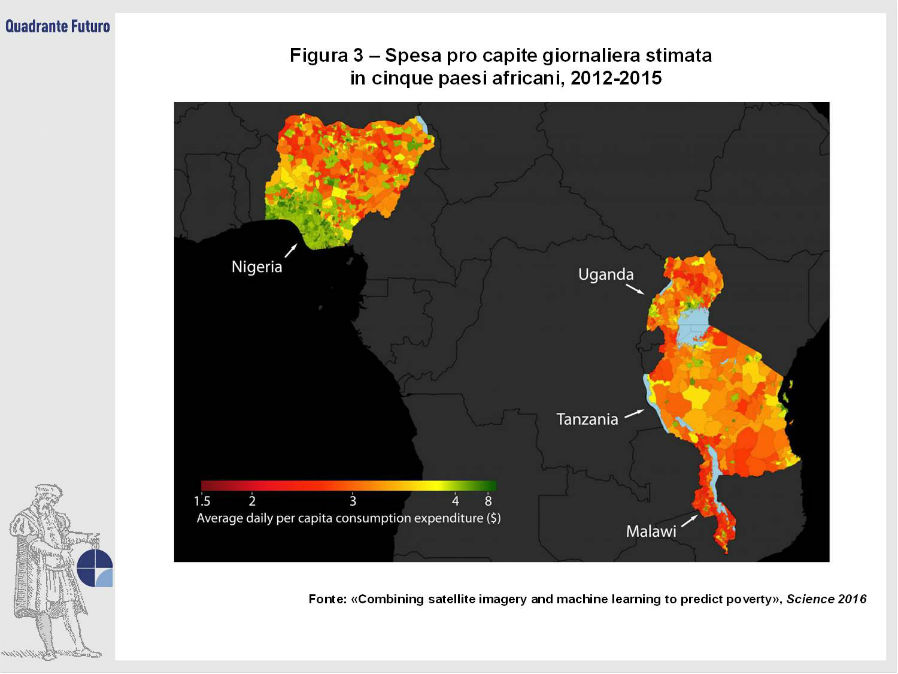
La molteplicità di fonti di informazioni non convenzionali e il progresso nelle tecnologie di machine-learning (capacità autodidattica dei computer) e analisi di dati sta però oggi offrendo interessanti alternative alla raccolta tradizionale dei dati. Un team di ricercatori dell’Università di Stanford ha messo a punto un sistema basato sulle immagini provenienti dai satelliti in grado di mappare il livello di povertà delle zone analizzate. Il software sovrappone le informazioni delle immagini notturne (un più alto livello di luminosità è tipicamente correlato con una maggiore attività economica) con quelle diurne, grazie alle quali vengono identificati automaticamente numerosi indicatori di sviluppo, come strade, aree urbane, acquedotti e fattorie, e tramite potenti algoritmi viene stimato il livello di sviluppo raggiunto da ogni villaggio.
Il sistema dell’Università californiana è già stato testato su cinque paesi africani (Uganda, Tanzania, Nigeria, Malawi e Rwanda), nei quali era presente un completo database di informazioni socio-economiche con cui confrontare i risultati ottenuti (Figura 3). Secondo gli ideatori del progetto i risultati sono stati estremamente affidabili e l’algoritmo è pronto per essere replicato a livello globale, praticamente senza costi aggiuntivi.
Anche i dati riguardanti il traffico telefonico, solitamente la forma di comunicazione primaria nei paesi in via di sviluppo, sono stati recentemente utilizzati per fornire indicazioni in real-time riguardo alle condizioni socio-economiche della popolazione.
Se esaminiamo la situazione nelle economie avanzate, la montagna di dati e la potenza di calcolo recentemente resa disponibile sta offrendo interessanti alternative alle tradizionali misurazioni economiche. Qui, a differenza dei paesi in via di sviluppo, il problema non è tanto la mancanza dei dati, quanto la loro tempestività e accuratezza.
Misurare l’attività economica non è infatti immediato come osservare le condizioni metereologiche: si tratta di tracciare e misurare milioni di transazioni e attività che prendono luogo in un’immensa area geografica. Per questo motivo i dati ufficiali vengono pubblicati dagli Istituti di statistica con una frequenza non molto elevata. Ad esempio i dati relativi al PIL sono tipicamente resi pubblici tra le quattro e le sei settimane dopo la fine di ogni trimestre, e la prima pubblicazione è spesso suscettibile di successive revisioni. Questi lunghi lassi di tempo possono avere importanti conseguenze, costringendo policy-maker e settore privato a prendere decisioni ignorando quali siano i mutamenti più recenti nello stato dell’economia. Un chiaro esempio di questa situazione si è materializzato dopo il voto britannico del 23 giugno, che ha indirizzato la Gran Bretagna verso un periodo di forte incertezza economica. Nonostante in seguito al referendum la Bank of England e gli investitori della piazza di Londra fossero ansiosi di ottenere informazioni riguardo alle conseguenze economiche di breve periodo della Brexit, i dati ufficiali su PIL e consumi del secondo quadrimestre sono stati pubblicati solamente il 26 agosto (e comprendevano un brevissimo lasso di tempo successivo al referendum), mentre per quelli sul mercato del lavoro si è dovuto attendere il 14 settembre.
Per ovviare alla lentezza nel calcolo degli hard-data (dati effettivi) la soluzione tradizionale è stata quella di affiancare le fonti di informazioni ufficiali con delle frequenti misurazioni della confidenza di consumatori e imprese (soft-data). Questi, trattandosi di opinioni e non di fatti, seppur fortemente correlate con la vivacità dell’attività economica, sono spesso suscettibili di una volatilità non sempre collegata con lo stato dell’economia sottostante.
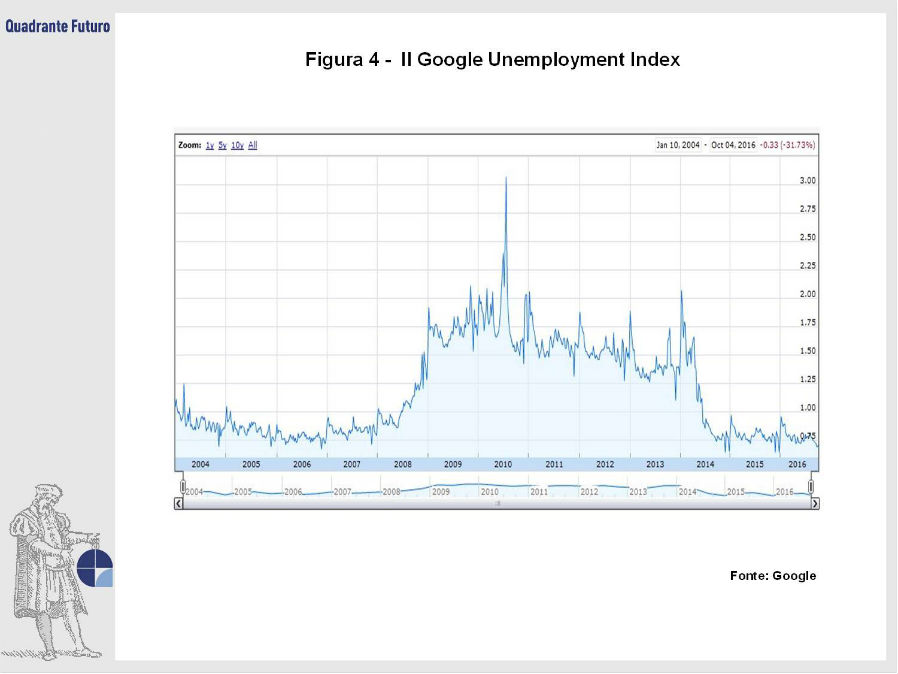
Anche in questo caso l’analisi dei big data può fornire alcune soluzioni innovative. Un diverso strumento per valutare la disoccupazione è il Google Unemployment Index (Figura 4), un algoritmo in grado di stimare il tasso di disoccupazione di un’economia utilizzando le ricerche internet di alcune parole, come disoccupazione, buoni pasto, e sicurezza sociale: un aumento di tali ricerche segnala una crescita del tasso di disoccupazione. Altre importanti indicazioni sul mercato del lavoro possono essere ottenute tramite l’analisi dei dati forniti dai siti di annunci di lavoro. Adzuna, il più grande sito di job-seeking britannico, pubblica mensilmente un report sullo stato del mercato del lavoro, grazie al quale è possibile calcolare variabili come l’offerta di lavoro, lo skill gap (la durata media in cui le posizioni rimangono aperte indica un mancato incontro tra domanda e offerta di competenze) e, non ultima, la variazione nei salari. Nelle settimane successive alla Brexit il numero di offerte di lavoro su Adzuna ha avuto un trend positivo, fornendo segnali incoraggianti riguardo alla resilienza dell’economia britannica al voto.
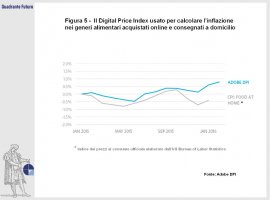
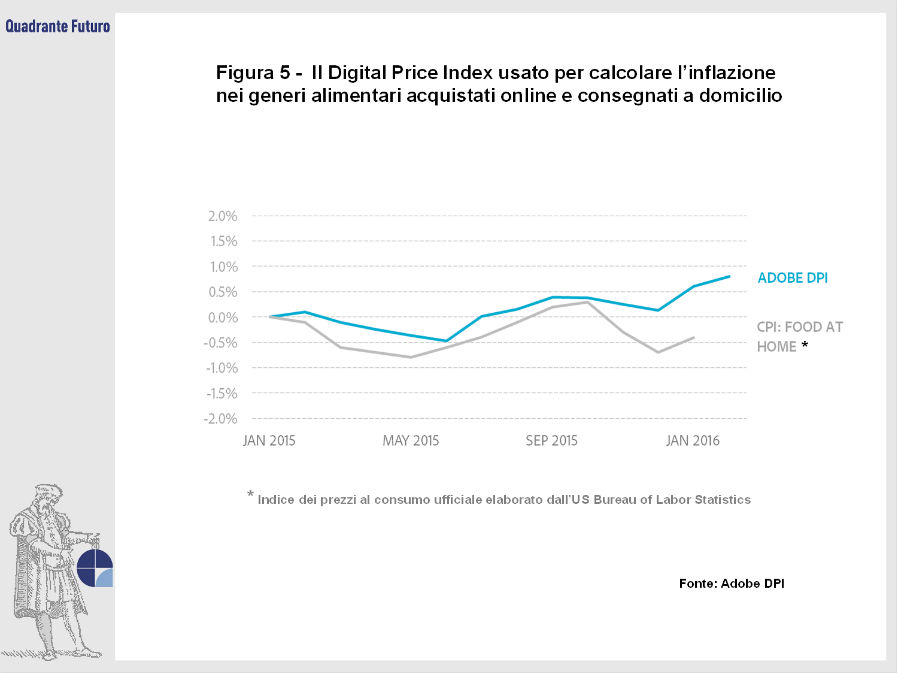
Tramite l’analisi delle vendite sui siti di e-commerce, su cui ogni anno transitano scambi per oltre mille miliardi di euro, è possibile ottenere stime riguardo il tasso di inflazione e il livello dei consumi. Adobe, divenuto un importante fornitore di software analitici per i rivenditori online, ha lanciato l’Adobe Digital-Economy Project, che sfrutta la mole di dati accumulati per stimare rapidamente numerose variabili economiche, tra cui proprio la variazione dei prezzi dei beni di consumo e di quelli immobiliari tramite il Digital Price Index (Figura 5) e l’Housing Price Index.
Now-Casting Economics, una società londinese, ha messo a punto un modello econometrico in grado di fornire una visione complessiva dello stato dell’economia sfruttando un set di oltre 50 variabili, oggi utilizzato da numerose Banche Centrali ed Hedge Funds. La caratteristica più pregiata di questo modello è la sua capacità di identificare le sinergie nei movimenti degli indicatori analizzati; così facendo è possibile eliminare gli elementi di disturbo presenti nella maggior parte dei dati economici e prevedere le variabili di interesse. “Dal consumo di energia elettrica è possibile risalire alla produzione manifatturiera” spiega Josper McMahon, CEO di Now-Casting Economics, che descrive il modello della società come una “Macchina che estrae segnali dalle notizie economiche”, fornendo i valori dei principali indicatori economici con settimane o addirittura mesi di anticipo rispetto ai dati ufficiali.
Il Nowcasting, da now (ora) e forecasting (prevedere) è così oggi una nuova branca dell’economia, che sfrutta la potenza di calcolo dei computer per tentare di misurare l’attività economica in tempo reale. Il fisico danese Niels Bohr soleva spesso scherzosamente dire che “Fare previsioni è una cosa molto difficile, specialmente se riguardano il futuro”; in economia, invece, le previsioni sono difficili anche sul presente.
© Riproduzione riservata








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}