Mentre pubblichiamo l’aggiornamento giornaliero dell'indice Rt, in discesa, apprendiamo che l’ISS ha pubblicato i dati, una spiegazione di come si calcola l’Rt da parte di Stefano Merler (Fondazione Bruno Kessler) e il codice che esegue i calcoli, a cura di MRC Centre for Global Infectious Disease Analysis hosted within the Department of Infectious Disease Epidemiology at Imperial College London. Bene per i dati, per la spiegazione e per il codice: era da marzo che li aspettavamo. Provvederemo a breve a far girare il codice sui dati italiani e verificare i risultati.
Le nostre valutazioni
Nel frattempo, qualche risposta alle considerazioni riportate nella spiegazione, sul calcolo Rt in tempo reale, nella penultima pagina. Viene detto che le stime di R(t) in tempo reale, ciò che stiamo facendo noi di Mondo Economico, sono imposssibili, a meno di:
1. ”forzare” i dati con tecniche di “data imputation”
2. velocizzare enormemente il processo di raccolta ed informatizzazione dei dati. Sotto un certo limite, tempo da sintomi a prima visita, non si può scendere
3. intendersi sul significato delle stime
Inoltre, viene sottolineato che è «saggio non fornire stime per gli ultimi 10-15 giorni».
Chiederei innanzitutto all’ISS e alla Fondazione di spiegare al titolare del bar vicino al mio ufficio che deve rimanere chiuso per altre tre, due, o forse no, quattro settimane, perchè, stando alla letteratura, è «saggio non fornire stime per gli ultimi 10-15 giorni» (che poi sono 3 settimane).
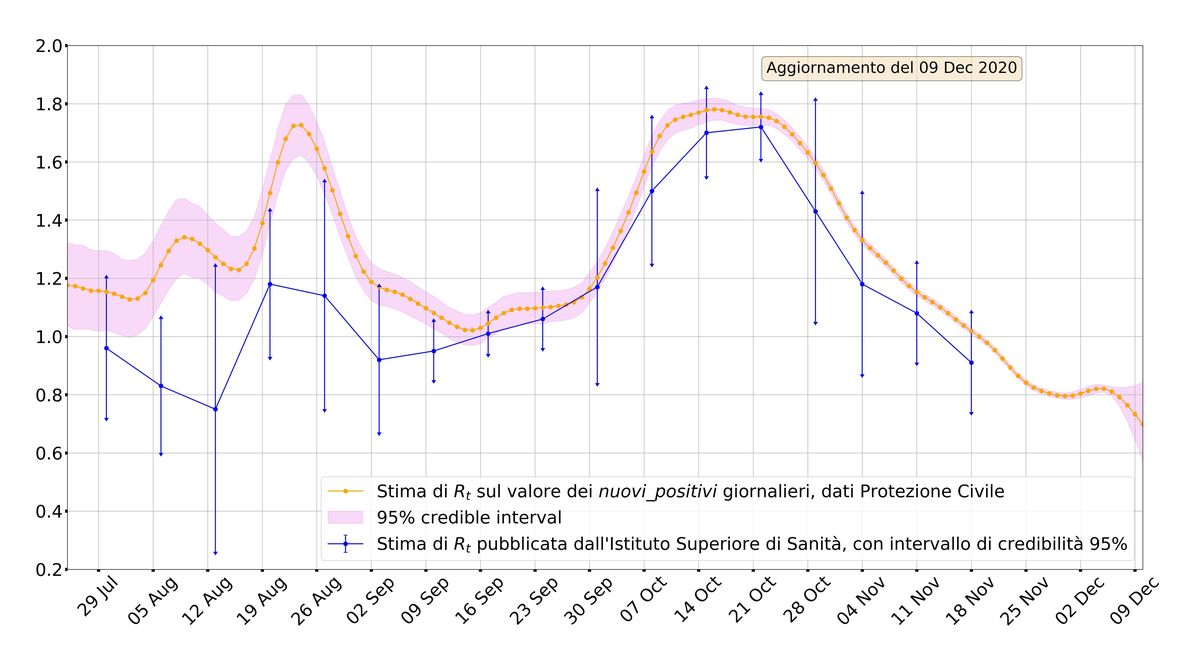
Di fronte a un grafico perfettamente allineato con i dati ufficiali come quello qui sopra, riteniamo doveroso, da parte di un ente pubblico, impegnare tempo e risorse per capire come funziona il metodo proposto, studiare il codice (pubblico) e misurare l’errore commesso dall’approssimazione proposta, invece di rispondere con una powerpoint fatta di copia e incolla senza né data né numeri di pagina.
I metodi di lavoro
Non siamo i soli a proporre metodi di questo tipo: epiforecasts.io e rt.live, che calcolano l’Rt giornaliero per tutto il mondo e per gli Stati Uniti rispettivamente (anche il loro codice è disponibile) adottano metodi simili al nostro.
Fanno data imputation (qui per i non addetti)? Non mi interessa come si chiama, mi interessa come funziona quello che fanno, e sono andato a vedere il codice per capirlo, da qui la richiesta iniziale dei dati all’ISS, per replicare lo stesso metodo in Italia: utilizzare la conoscenza pregressa del ritardo tra data di comparsa dei sintomi e data di segnalazione, per ricostruire la prima sulla base della seconda e poi calcolare l’Rt sulla data inizio sintomi stimata. Nota la distribuzione del ritardo, si calcola la convoluzione tra questa distribuzione e la distribuzione dei nuovi positivi (data segnalazione), e a quel punto si conosce l’intervallo di confidenza con cui sono stimati i casi più recenti non ancora segnalati. E’ un metodo perfetto? No, ma fornisce un intervallo di confidenza, ne più ne meno di quanto già succede con i dati ufficiali dell’ISS. Quindi? Non abbiamo le risorse per fare due calcoli e vedere quanto viene l’intervallo di confidenza prodotto dalla stima del ritardo?
Peraltro, nella spiegazione, non troviamo traccia del problema che abbiamo sollevato sugli intervalli di confidenza artificialmente amplificati dal fatto di calcolarli su 14 giorni, e sulla relativa proposta di soluzione che abbiamo proposto.
Quanto ad intendersi sul significato delle stime (è facile, basta accordarsi sull'intervallo di confidenza), noi ci siamo. Rinnoviamo la nostra disponibilità per un confronto e abbiamo chiesto i dati proprio per valutare l’approssimazione della data di inizio contagiosità con la data di rilevazione.
Ci sembrerebbe più efficiente fare questa valutazione insieme all'ISS e alla Fondazione. In ogni caso procederemo, tenendo aggiornati i nostri lettori.
© Riproduzione riservata







