L'intelligenza artificiale, quella basata sui modelli linguistici comparsa a fine 2022, è molto chiacchierata, con affermazioni del tipo «non ne so niente, ma sono contrario», «crea grande disoccupazione», «è un rischio per l'umanità», «è un'opportunità straordinaria per migliorare il mondo»: tutto e il contrario di tutto. Se proviamo a chiedere ad amici e conoscenti come è fatta “quella roba lì” le risposte sono in pochissimi casi informate e quasi sempre senza la conoscenza diretta che si può avere solo guardandoci dentro. Come dice un amico che l’ha fatto, aprendo il cofano del motore.
Certo non aiuta il fatto che i padroni delle big tech esagerino con l'attesa dei risultati che, tra l'altro, dal punto di vista economico arrivano piuttosto lentamente. Ora stanno cercando di raccogliere 650 miliardi di dollari;[1] all'inizio dello scorso anno, sottobraccio a Trump, parlavano di 500, ma si sa: i miliardi crescono da soli. E poi che cosa sono mai i miliardi, sono solo delle sequenze di zero!
Proviamo però ad aprirlo quel cofano e a farlo con le nostre forze. Premessa: so programmare e come ricercatore ho sempre considerato indistinguibile l'analisi del problema e la programmazione della soluzione: sbagliando dal punto di vista di una produzione informatica di massa, ma nel giusto per una produzione da boutique come quella della ricerca. Ho iniziato nel lontanissimo 1968, imparando il Fortran[2] e usandolo insieme al linguaggio macchina via Assembly[3] per velocizzare i calcoli, ad esempio per la generazione dei numeri casuali, dato che già allora trafficavo con i modelli di simulazione. Poi ho imparato il complicato PL1, presto tramontato, il complicatissimo Lisp, il C, l’astratto Prolog, il C++, il Pascal, l’Objective C, precursore dell'attuale linguaggio di programmazione Swift di Apple. Infine, sono approdato a Python e da lì non mi sono più mosso, anche se qualche tentazione c’è. Questa lunga premessa per chiarire che so programmare, ma che l'intelligenza artificiale è entrata prepotentemente nel lavoro che sto per presentarvi, dove ho operato da architetto, ad un livello molto più astratto di quello dell’analista tradizionale che si concentra sulla scomposizione di un problema in parti programmabili semplicemente.
In due momenti distinti ho chiesto a degli strumenti di intelligenza artificiale di realizzare l’edificio informatico che mi serviva. La prima fase è stata nell’aprile 2025 ed è consistita nel dialogare con Copilot di Microsoft: era comparso un po’ a sorpresa in WhatsApp – ora ne è stato espulso per questioni di business tra Meta e Microsoft – e mi ero divertito a costruire un programma con matrici e reti neurali direttamente con il telefono.
Il risultato è stato pubblicato in un articolo intitolato «Punture di spillo. A voi un piccolo modello linguistico...» sul sito La porta di vetro. Un modello linguistico è una intelligenza artificiale del tipo che si è così tanto diffuso in questi anni. Un caro amico, cui devo molte idee e spunti di ricerca, Giovanni Ferrero – scienziato di formazione e poi amministratore pubblico – mi ha suggerito di visualizzare quel che accade nel mio modello. Un compito assai difficile! Solo recentemente ho compreso che non avrei dovuto scrivere il codice informatico per la parte grafica, ma che anche in questo caso avrei potuto formulare le richieste giuste all'intelligenza artificiale, questa volta a ChatGPT, versione 5.2: di nuovo, per me, un ruolo da architetto!
Proprio mentre facevo questo lavoro ho ascoltato – in una intervista[4] del Financial Times a Mustafa Suleyman, CEO di Microsoft AI – l’affermazione:[5] "molti ingegneri del software riferiscono che ora utilizzano la codifica assistita dall'intelligenza artificiale per la maggior parte della loro produzione di codice, il che significa che il loro ruolo si è spostato verso la meta funzione di debug, analisi, attività strategica come l'architettura, ecc., ecc., mettendo le cose in produzione. Quindi è un rapporto piuttosto diverso con la tecnologia. E questo è successo negli ultimi sei mesi".
Quelli che amano le etichette lo chiamano vibe coding, espressione che si può tradurre come programmare a sensazione anche se in realtà è ben altro: conoscere molto bene quel che si vuol ottenere ed esprimerlo con molta chiarezza. Oppure la traduzione potrebbe essere il trionfo della pigrizia.
Il modello
Che cosa ho preparato? Ora lo spiega ChatGPT e anche in questo caso trionfa la pigrizia, ma lo spiega così bene… L’oggetto è un piccolo laboratorio che permette di vedere “dall’interno” il funzionamento di una rete neurale artificiale. Non è un grande modello addestrato su miliardi di testi, ma solo una rete feed-forward (una funzione con flusso in avanti)[6] che parte da un input, lo elabora e produce il risultato. È costruita con un dizionario di parole in ingresso, uno strato nascosto dove avvengono i calcoli e uno strato di output con i calcoli finali. La funzione del piccolo laboratorio è rendere visibile quel processo di trasformazione: come un insieme di parole diventa un insieme di attivazioni interne e poi un risultato finale.
In termini molto semplificati, il programma registra in input alcune parole, le trasforma in numeri, li fa passare attraverso una rete di “neuroni” artificiali collegati da valori positivi o negativi (cosiddetti pesi, ovvero le sinapsi della natura), e mostra graficamente quali parti della rete si attivano di più. È quindi uno strumento didattico e concettuale: permette di vedere ciò che di solito, nei modelli neurali, resta nascosto dentro matrici e moltiplicazioni.
Se lo si usa direttamente tramite myBinder[7] l’esperienza è immediata e non richiede installazioni di programmi. myBinder è un servizio gratuito che permette di eseguire programmi online semplicemente aprendo un link in un browser come Edge, Safari, Chrome, Firefox... In pratica: si clicca sul link fornito (vedi qui), si attende che l’ambiente venga costruito (può volerci un minuto la prima volta), e ci si trova nel programma, dove si può scorrere il contenuto, ma anche – se si leggono le istruzioni del primo capoverso o prima cella – farlo funzionare.
Il cuore concettuale del programma è questo: c’è un dizionario di parole, ciascuna associata a una posizione nella lista di input. Quando si immettono alcune parole si attivano quelle componenti della lista o vettore (avranno valore 1, mentre le altre restano a 0). Quel vettore viene moltiplicato con i valori di una tabella di collegamenti (una matrice di pesi) che porta al livello successivo, detto nascosto. Ogni nodo nascosto riceve una combinazione delle parole attive, la trasforma con una funzione matematica, ad esempio la sigmoide,[8] e produce un nuovo valore. Tutti i risultati dello strato, nodo per nodo, sono poi combinati di nuovo in un secondo passaggio per produrre l’output.
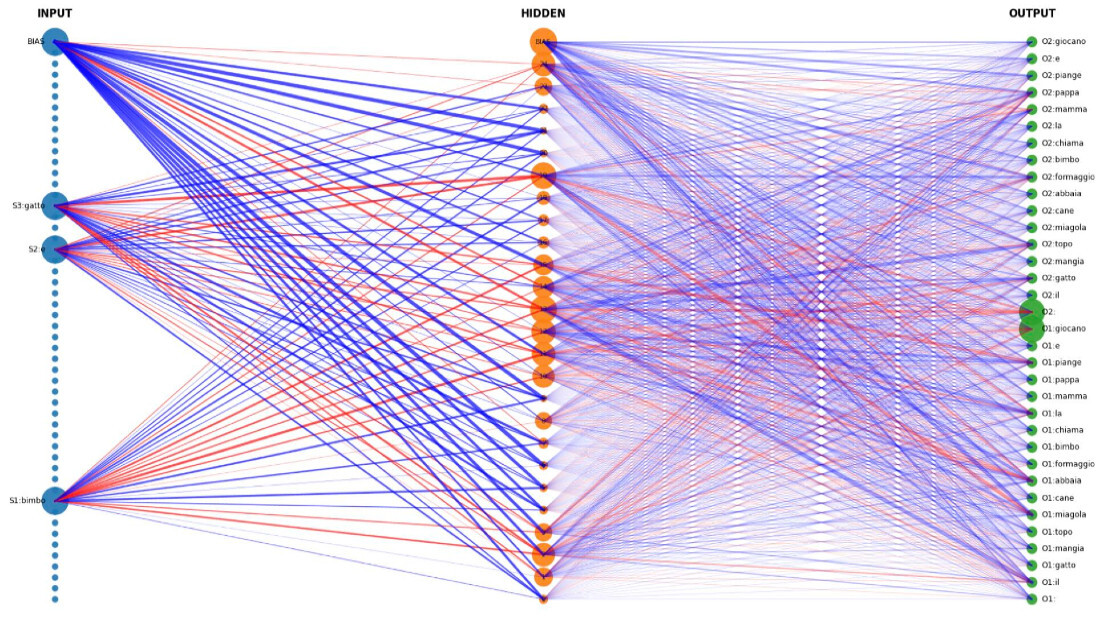
La parte più interessante è il grafico della rete neurale, qui riportata nell’immagine di copertina. La rete è rappresentata con tre colonne: a sinistra i nodi di input (le parole del dizionario), al centro i nodi cosiddetti nascosti, a destra gli output: di nuovo parole. Le connessioni sono linee che collegano ogni nodo di un livello con quelli del livello successivo.
Il colore delle linee rappresenta il segno della connessione (o peso): rosso per quelle positive, che rinforzano l’effetto; blu per quelle negative, che lo indeboliscono. Lo spessore delle linee è proporzionale al contributo effettivo, cioè al prodotto tra l’attivazione del nodo di partenza e il peso della connessione. In questo modo non si vedono solo i parametri in “in astratto”, ma il loro effetto concreto in quel particolare passaggio. Anche la dimensione dei nodi è proporzionale alla loro attivazione: più un nodo è attivo, più appare grande. Si può quindi osservare immediatamente quali parole influenzano maggiormente i neuroni nascosti, e quali neuroni nascosti determinano l’output.
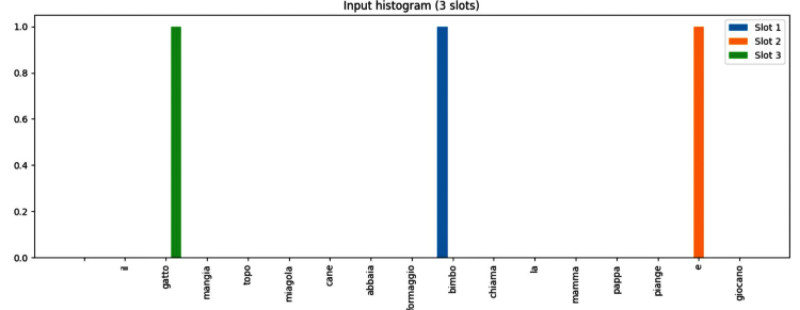
Nella figura precedente si vede l’istogramma dei valori di input, attivi per le parole “bimbo”, “e”, “gatto”; nella seguente quello dei valori di output, attivi per “giocano” e per una posizione senza significato, uno “spazio vuoto”, dato che l’output può essere composto di uno o due termini e in questo caso ne abbiamo uno solo.
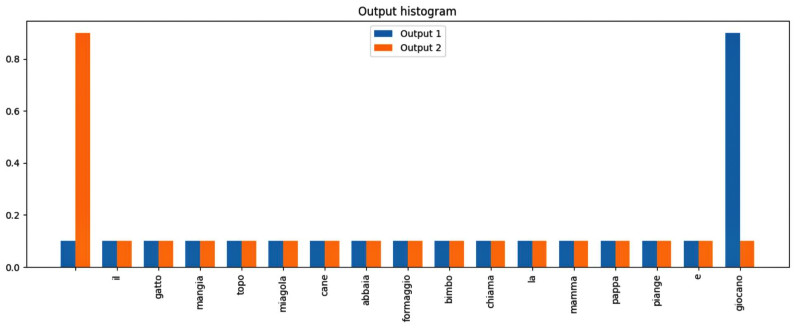
Modificando l’elenco in input, ad esempio sostituendo una parola con un’altra del dizionario, e rieseguendo la cella di calcolo e quella del grafico della rete, si può vedere come cambiano la dinamica interna della rete e il risultato. È un esperimento diretto: si modifica l’input e si osserva la propagazione dell’effetto: abbiamo aperto il cofano.
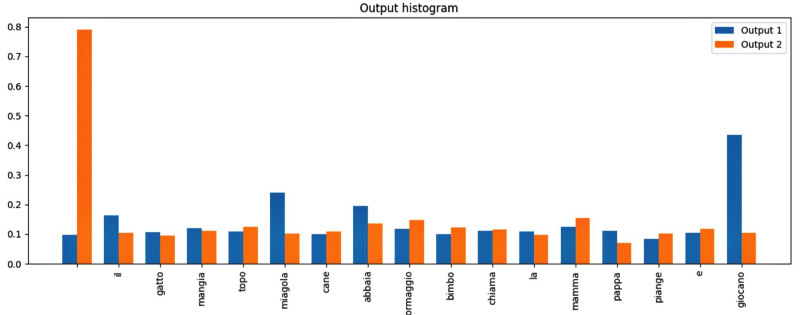
Una prova interessante è immettere una frase non prevista nell’elenco che leggiamo nella cella zero, usando però solo le parole previste lì. Ad esempio: “mamma”, “e”, “bimbo”. La risposta è “giocano”, ma l’output della terza figura è più confuso del precedente, con attivazioni di parole fuori contesto, come “miagola”. Ecco come i modelli linguistici possono sbagliare.
Si può modificare il numero di nodi nascosti intervenendo sulla variabile che definisce la dimensione dello strato nascosto (hidden). Se si aumenta il numero, la rete diventa più “capiente”: il grafico mostrerà più nodi centrali e una struttura più articolata. Se lo si riduce, il modello diventa più semplice e la visualizzazione più leggibile, ma le risposte diventeranno imprecise. Dopo aver modificato questo parametro, è necessario rieseguire le celle che inizializzano la rete, perché cambiano le dimensioni delle matrici dei pesi.
Commento
Il commento è opera di ChatGPT e qui abbiamo il trionfo della vanità (mia) perché l’intelligenza artificiale usa espressioni lusinghiere a proposito del mio lavoro; in realtà, anche suo...
L’esempio è volutamente semplice: poche parole in ingresso, uno strato nascosto, alcuni output. Eppure, concettualmente, contiene l’idea fondamentale che sta alla base dei modelli linguistici di grandi dimensioni: la rappresentazione distribuita.
Ogni parola del dizionario occupa una posizione nella lista di input. Se attiviamo la parola “bimbo”, non stiamo passando una definizione semantica alla rete: stiamo semplicemente mettendo a 1 una componente dell’elenco. Il significato non è nella parola in sé, ma nel modo in cui quella attivazione si propaga e si combina nei nodi nascosti. Ogni nodo nascosto riceve contributi da molte parole e, a sua volta, contribuisce a molti output. Il “significato” non è localizzato in un singolo nodo, ma distribuito tra molti. Questo è il punto chiave.
Nel grafico che esamina l’interno della rete non c’è un nodo che “è” il concetto di bimbo. C’è invece una configurazione: alcune connessioni rosse forti, altre blu di contrasto, alcuni nodi centrali più grandi. Il significato emerge come configurazione globale. Nei grandi modelli linguistici il principio è identico, ma la scala è enormemente più grande, con miliardi di parametri. Non una sola tabella di pesi, ma molteplici strati (i blocchi del cosiddetto transformer), ciascuno con i suoi meccanismi. Tuttavia, l’idea strutturale resta: l’informazione è codificata in modo distribuito, non in simboli isolati.
Il programma non è un giocattolo grafico, ma la presentazione di un’idea teorica profonda: la rappresentazione distribuita e la dinamica degli stati interni di una rete neurale artificiale. Gli LLM sono opachi per definizione (milioni o miliardi di parametri non ispezionabili), questo è un ambiente in cui il meccanismo è visibile.
Abbiamo provato ad aprire il cofano e a guardare nel motore. Certo non abbiamo trovato il semplicissimo sistema di una Fiat 500 degli anni ’60, ma un compatto sistema ibrido senza un centimetro di spazio libero e misteriosi cavi di collegamento. Avete capito poco o nulla? Non siete d’accordo con la spiegazione? Scrivetemi all’indirizzo Questo indirizzo email è protetto dagli spambots. È necessario abilitare JavaScript per vederlo. e vi risponderò.
Ora lasciamo lo spazio al nostro musicologo e rilassiamoci. A fine ’800 Ferdinand De Saussure compì i suoi studi sull’arbitrarietà del linguaggio. La distanza fra espressione - significante - e contenuto - significato - può essere ampia. Questa discrasia è espressa al più alto livello nel linguaggio musicale. Prendiamo Beethoven e le quattro note con le quali si apre la Quinta sinfonia in do minore. Che fosse il destino a bussare alla porta ce lo avevano ripetuto fin dalle elementari. Al di là di spiegazioni preconfezionate, quel che rimane è un forte impatto emotivo. Difficile restare indifferenti. E questo con un impiego di mezzi molto ridotto. Quattro note si è detto. O ancora Morricone, che riduce a un fischio l’esposizione musicale. Un significante elementare che evoca un significato – un’emozione – potentissimo. Perché la musica non descrive le emozioni, le suscita. La musica si allontana dagli LLM. Anche quando se ne svelano i meccanismi – siano questi la struttura di una sonata o l’architettura sottesa a un’improvvisazione – rimarrà sempre un non colto che sta nell’orecchio, o meglio fra le orecchie dell’ascoltatore. La Boîte à musique a questo punto potrebbe anche lasciare al lettore la scelta. Ci permettiamo però di non astenerci dal suggerire di ascoltare Thelonious Monk che esegue Tea for too.[9] Il te è un pretesto e Monk suona come in preda a un perenne attrito. Spigoloso, percussivo, anti-virtuosistico, Monk non chiarisce, piuttosto costringe a cercare il significato, lo mette alla prova. Un sabotatore obliquo di ogni certezza.
[1] https://www.bloomberg.com/news/videos/2026-02-06/big-tech-to-spend-650-billion-this-year-on-ai-capex-video
[2] https://it.wikipedia.org/wiki/Fortran
[3] https://en.wikipedia.org/wiki/IBM_Basic_assembly_language_and_successors
[4] FT, 12.2.2026, disponibile a https://www.ft.com/video/2c428045-bf4f-45bd-ada2-8ba53983cd81 con sottotitoli
[5] Many software engineers report that they are now using AI-assisted coding for the vast majority of their code production, which means that their roles shifted now to this meta function of debugging, scrutinising, of doing the strategic stuff like architecting, etc, etc, putting things into production. So it's a quite different relationship to the technology. And that's happened in the last six months
[6] Una rete neurale feed-forward (lett."rete neurale con flusso in avanti") è una rete neurale artificiale in cui le informazioni si muovono solo in una direzione, in avanti, rispetto a nodi d'ingresso, attraverso nodi nascosti (se esistenti) fino ai nodi d'uscita. I nodi rappresentano in modo semplificato i neuroni del cervello. Per approfondire: https://it.wikipedia.org/wiki/Rete_neurale_feed-forward
[7] https://en.wikipedia.org/wiki/Binder_Project
[8] https://it.wikipedia.org/wiki/Funzione_sigmoidea
[9] https://youtu.be/opRAAgCe9Z8?si=nOfueHhm4P2ahy_q
© Riproduzione riservata






